



Merhaba
SensorLM’i : 60 milyon saatlik veri üzerinde eğitilmiş, çok modlu giyilebilir sensör sinyallerini doğal dil ile ilişkilendirerek sağlığımızı ve aktivitelerimizi daha derinlemesine anlamayı sağlayan yeni bir sensör–dil taban modeli ailesi.
Akıllı saatlerden fitness takip cihazlarına kadar giyilebilir cihazlar hayatımızın her alanında yaygınlaştı ve sürekli olarak yaşamımıza dair zengin veri akışları topluyor. Kalp atış hızımızı kaydediyor, adımlarımızı sayıyor, egzersiz ve uyku düzenimizi takip ediyor ve çok daha fazlasını yapıyorlar. Bu bilgi seli, kişiselleştirilmiş sağlık ve zindelik için muazzam bir potansiyel barındırıyor.
Ancak, vücudumuzun ne yaptığına dair verileri kolayca görebilsek de (örneğin, dakikada 150 atımlık bir kalp ritmi), bunun neden olduğu gibi hayati bağlam (örneğin, “dik bir yokuşta hızlı bir koşu” ile “yoğun stresli bir topluluk önünde konuşma” arasındaki fark) çoğu zaman eksiktir. Bu ham sensör verisi ile gerçek dünya anlamı arasındaki boşluk, bu cihazların potansiyelini tam olarak açığa çıkarmanın önündeki en büyük engellerden biridir.
Bu zorluğun temelinde, sensör kayıtlarını zengin ve açıklayıcı metinlerle eşleştiren büyük ölçekli veri kümelerinin yetersizliği yatıyor. Milyonlarca saatlik veriyi elle açıklamak aşırı derecede maliyetli ve zaman alıcıdır. Bu sorunu çözmek ve giyilebilir verinin adeta “kendi adına konuşmasını” sağlamak için, sensör sinyalleri ile insan dili arasındaki karmaşık bağlantıları doğrudan veriden öğrenebilecek modellere ihtiyacımız var.
“SensorLM: Giyilebilir Sensörlerin Dilini Öğrenmek” başlıklı çalışmamızda, bu ihtiyaca yanıt olarak SensorLM’yi tanıtıyoruz: sensör–dil tabanlı yeni bir model ailesi. SensorLM, 103.000’den fazla bireyden toplanmış benzersiz 59,7 milyon saatlik çok modlu sensör verisi üzerinde önceden eğitilmiştir. Model, yüksek boyutlu giyilebilir veri akışlarını yorumlamayı ve bunlardan insan tarafından okunabilir, incelikli açıklamalar üretmeyi öğrenerek, sensör verisini anlamada yeni bir seviye ortaya koymaktadır.
SensorLM, istatistiksel, yapısal ve anlamsal boyutlar boyunca karmaşık ve çok modlu giyilebilir sensör verilerini anlamlı, doğal dil açıklamalarına dönüştürür.
SensorLM Modellerinin Eğitimi
SensorLM için gerekli sensör veri kümesini oluşturmak amacıyla, 127 farklı ülkeden 103.643 kişiye ait yaklaşık 2,5 milyon insan-günü kadar anonimleştirilmiş veri örneği alındı. Bu veriler, 1 Mart – 1 Mayıs 2024 tarihleri arasında Fitbit veya Pixel Watch cihazları aracılığıyla toplandı. Katılımcılar, anonimleştirilmiş verilerinin sağlık ve bilim hakkında genel bilgiye katkı sağlamak amacıyla araştırmalarda kullanılmasına onay verdiler.
Elle açıklama (etiketleme) ihtiyacının oluşturduğu darboğazı aşmak için, verilerden otomatik olarak açıklayıcı metin başlıkları (captions) üreten yenilikçi bir hiyerarşik işlem hattı geliştirdik. Bu sistem; istatistikleri hesaplayarak, eğilimleri tanımlayarak ve olayları betimleyerek sensör verilerinden açıklamalar üretmektedir.
Bu süreç sayesinde, şimdiye kadar oluşturulmuş en büyük sensör–dil veri kümesini hazırlamayı başardık. Üstelik bu veri kümesi, önceki çalışmalarda kullanılanlardan kat kat daha büyük bir ölçeğe sahiptir.
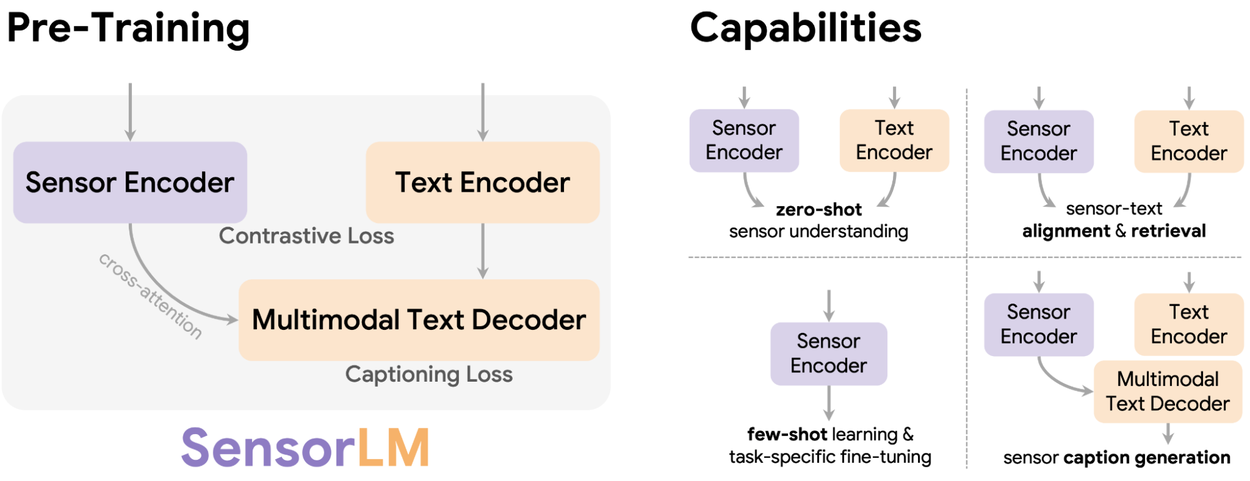
SensorLM’nin ön eğitimi, kişiselleştirilmiş içgörüler için yeni yetenekler kazandırır; bunlar arasında sıfır örnekle (zero-shot) sensör verisi anlama, sensör–metin hizalaması ve geri getirme (retrieval), az örnekle öğrenme (few-shot learning) ve sensör verisinden açıklama üretimi (caption generation) yer alır.
SensorLM mimarisi, önde gelen çok modlu ön eğitim stratejilerini – özellikle karşılaştırmalı öğrenme (contrastive learning) ve üretici ön eğitim (generative pre-training) yaklaşımlarını – temel alır ve bunları tek bir bütünleşik çerçevede birleştirir.
Karşılaştırmalı Öğrenme:
Model, bir grup seçenek arasından bir sensör veri segmentini ilgili metin açıklamasıyla eşleştirmeyi öğrenir. Bu yaklaşım, modelin farklı etkinlik ve durumları ayırt etmesini sağlar (örneğin, “hafif yüzme” ile “ağırlık antrenmanı”nı birbirinden ayırmak gibi).
Üretici Ön Eğitim:
Model, sensör verisinden doğrudan metin açıklamaları üretmeyi öğrenir. Bu sayede, yüksek boyutlu sensör sinyallerini anlayarak, zengin ve bağlama duyarlı açıklamalar oluşturma yeteneği kazanır.
Bu iki yaklaşımı tek, tutarlı bir mimaride bütünleştirerek, SensorLM; sensör sinyalleri ile dil arasındaki ilişkiyi çok modlu ve derinlemesine kavrayabilen bir model hâline gelir.
Temel Yetkinlikler ve Ölçeklenme Davranışları
SensorLM’i, insan aktivitesi tanıma ve sağlık alanındaki çok çeşitli gerçek dünya görevleri üzerinde değerlendirdik. Elde edilen sonuçlar, önceki son teknoloji (SOTA) modellere kıyasla önemli ilerlemeler gösterdi.
Aktivite Tanıma ve Geri Getirme (Retrieval)
SensorLM, etiketli verinin sınırlı olduğu görevlerde üstün performans sergiliyor.
- Zero-shot sınıflandırma (sıfır örnekle tanıma):
Model, herhangi bir ek ince ayar yapılmadan, 20 farklı aktiviteyi yüksek doğrulukla sınıflandırabiliyor. - Few-shot öğrenme (az örnekle öğrenme):
Sadece birkaç örnekle hızlı şekilde yeni aktiviteleri öğrenebiliyor.
Bu da modeli, yeni görev ve kullanıcı ortamlarına minimum veriyle uyarlanabilir hâle getiriyor.
Ayrıca SensorLM, güçlü çapraz-modalli geri getirme (cross-modal retrieval) yeteneklerine de sahiptir:
- Sensör verisini kullanarak açıklamaları sorgulamak,
- ya da doğal dil kullanarak belirli sensör desenlerini bulmak mümkündür.
Bu sayede uzmanların sensör verisini doğrudan doğal dille analiz etmesi kolaylaşır.
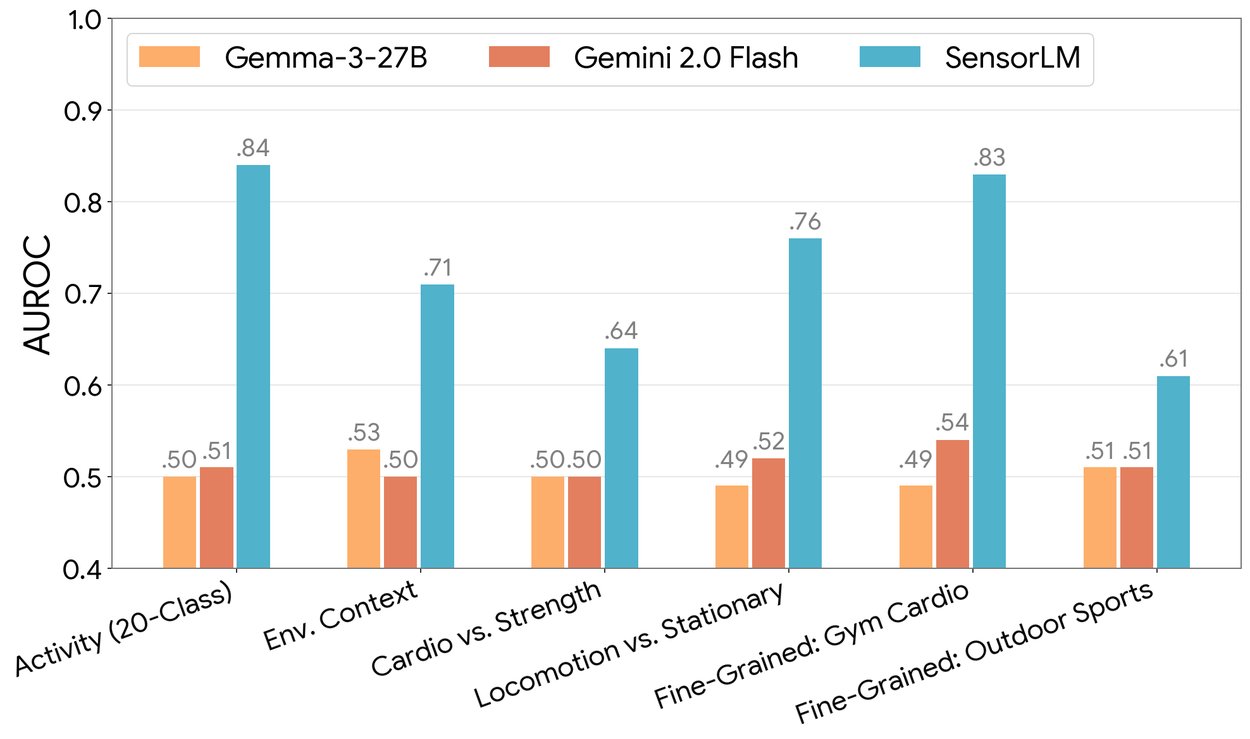
Sıfır örnekle insan aktivitesi tanıma (zero-shot human activity recognition) görevlerinde, SensorLM, görevler genelinde güçlü sıfır-shot yetenekler sergilemektedir (AUROC metriğiyle ölçülmüştür); buna karşın temel büyük dil modelleri (LLM’ler) ise neredeyse rastgele tahmin seviyesinde performans göstermektedir.
Üretici (Generative) Yetkinlikler
Sınıflandırma gücünün ötesinde, SensorLM aynı zamanda etkileyici açıklama (caption) üretme yetenekleri de sergilemektedir.
Yalnızca giyilebilir bir cihazdan alınan yüksek boyutlu sensör sinyalleri verilerek, SensorLM:
- Hiyerarşik ve
- bağlama uygun (contextual)
açıklamalar üretebilmektedir.
Yapılan deneysel sonuçlar, bu üretilen açıklamaların; güçlü fakat alan uzmanı olmayan büyük dil modelleri (LLM’ler) tarafından üretilenlere kıyasla:
- daha tutarlı ve
- daha gerçekçi (doğruluk açısından üstün)
olduğunu göstermiştir.
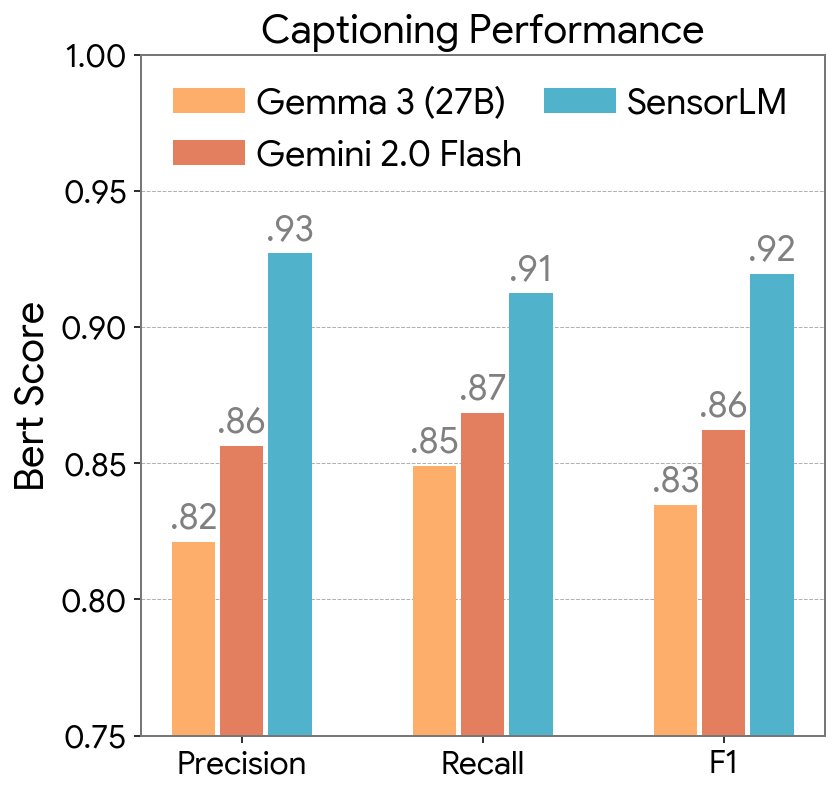
SensorLM ve karşılaştırma modellerinin (baselines) açıklama üretim performansı, BERTScore metriği kullanılarak (Kesinlik – Precision, Duyarlılık – Recall ve F1 skoru) ile ölçülmüştür.
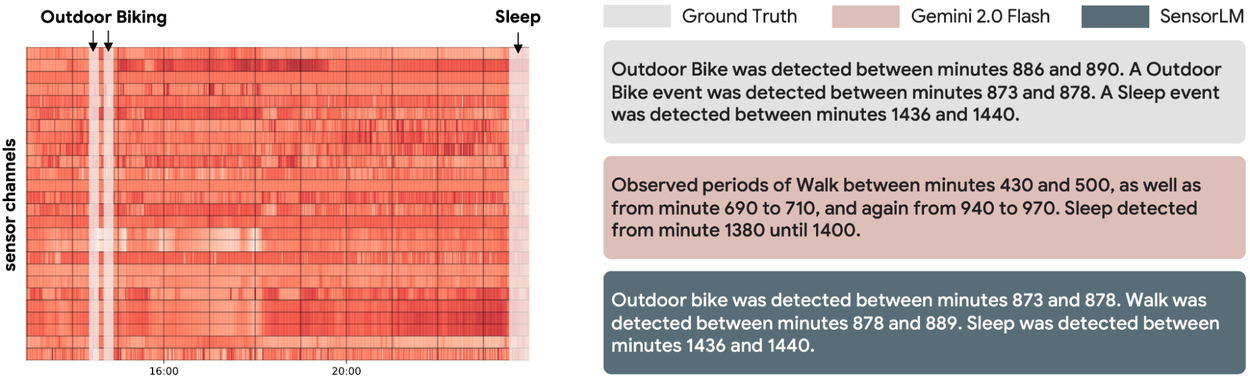
Sol: Girdi olarak verilen giyilebilir sensör verisi.
Sağ: Gerçek açıklama (ground truth) ve farklı modeller tarafından üretilen açıklamalar.
SensorLM, sensör verisinden doğrudan tutarlı ve doğru açıklamalar üretir; bu açıklamalar, genel amaçlı dil modellerine kıyasla daha ayrıntılı ve isabetlidir.
Ölçeklenme Davranışı
Yaptığımız deneyler, SensorLM’in performansının daha fazla veri, daha büyük model boyutları ve artan hesaplama gücü ile birlikte istikrarlı bir şekilde iyileştiğini ortaya koymuştur. Bu sonuçlar, mevcut ölçeklenme yasalarıyla (scaling laws) da uyum içindedir.
Bu sürekli gelişim, büyük ölçekli sensör–dil ön eğitimiyle mümkün olanların henüz yalnızca yüzeyine dokunduğumuzu göstermektedir. Bu da, bu paradigma üzerine daha fazla araştırma yapılmasının son derece değerli olacağını işaret etmektedir.
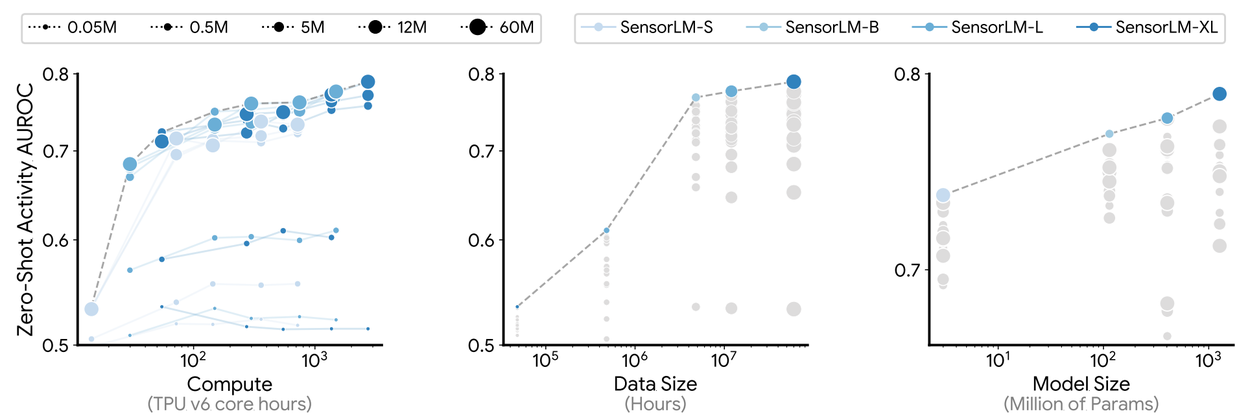
SensorLM modelleri üzerinde yapılan sistematik ölçekleme deneyleri aracılığıyla; artırılan işlem gücü (solda), veri miktarı (ortada) ve model boyutu (sağda) ile sıfır örnekle aktivite tanıma (zero-shot activity recognition) performansının tutarlı bir şekilde iyileştiğini gösteriyoruz.
Sonuç
Bu araştırmamız, giyilebilir sensör verilerini doğal dil yoluyla anlamlandırmaya yönelik temeli ortaya koymaktadır. Bu; yenilikçi bir hiyerarşik açıklama üretim süreci (captioning pipeline) ve bugüne kadar oluşturulmuş en büyük sensör–dil veri kümesi ile mümkün olmuştur.
SensorLM model ailesi, kişisel sağlık verilerinin anlaşılır ve eyleme dönüştürülebilir hâle getirilmesinde büyük bir ilerlemeyi temsil etmektedir. Yapay zekaya bedenimizin dilini anlamayı öğretmek, bizi yalnızca basit ölçüm verilerinin ötesine taşıyarak, gerçek anlamda kişiselleştirilmiş içgörüler sunabilme potansiyelini doğurmaktadır.
Gelecek Vizyonu
İleriye dönük olarak, ön eğitim verilerini metabolik sağlık, detaylı uyku analizi gibi yeni alanlara ölçeklemeyi planlıyoruz. Bu sayede tüketiciye yönelik sağlık cihazlarının karmaşık ve dağınık doğasını daha iyi ele alabileceğiz.
SensorLM’nin, gelecekte:
- doğal dille etkileşim kurabilen dijital sağlık koçları,
- klinik izleme araçları,
- ve kişisel sağlıklı yaşam uygulamaları gibi sistemlere ilham vereceğine inanıyoruz.
Bu araştırmadan doğabilecek herhangi bir ürün veya uygulama, klinik ve yasal düzenlemelere uygunluk açısından ayrıca değerlendirmeye tabi tutulmalıdır.
Teşekkür
Bu araştırma, Google Research, Google Health, Google DeepMind ve iş birliği yapan diğer ekiplerin ortak çalışmasıyla gerçekleştirilmiştir.
Çalışmaya katkıda bulunan araştırmacılar:
Yuwei Zhang, Kumar Ayush, Siyuan Qiao, A. Ali Heydari, Girish Narayanswamy, Maxwell A. Xu, Ahmed Metwally, Shawn Xu, Jake Garrison, Xuhai Xu, Tim Althoff, Yun Liu, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Cecilia Mascolo, Xin Liu, Daniel McDuff ve Yuzhe Yang


