


Merhaba
Yapay zekanın hızlı ilerlemesinin arkasındaki en büyük itici güçlerden biri, modellerin sürekli gelişmesini ve güvenilir şekilde çalışmasını sağlayan büyük ölçekli, yüksek kaliteli verilere erişimdir. Ancak bu kaynak tükeniyor. Kullanılabilir internet verilerinin azalmasıyla, yapay zekanın ihtiyaç duyduğu eğitim verilerini toplamak giderek daha zor ve maliyetli hale geliyor. Araştırmacılar bu zorluğa veri duvarı adını veriyor yani geliştirme sürecini yavaşlatan ve maliyetleri artıran bir engel.
Bu duvarı aşmak için birçok kişi sentetik veriye yöneliyor. Sentetik veri yapay olarak üretilmiş olsa da, gerçek dünya örüntülerini oldukça yakından taklit edebiliyor. Ancak şu ana kadar belirsiz olan konu, doğal verilerle çalışan modellerin performansını belirleyen ölçekleme yasalarının, sentetik veri için de geçerli olup olmadığıydı.
Doğal veri kümelerinde, büyük dil modelleri (LLM’ler), performans, model boyutu ve eğitim verisi miktarı arasında öngörülebilir bir güç yasası ilişkisi (power law) izler. Bu ilişki, araştırmacıların belirli kaynaklarla bir modelin ne kadar iyi performans göstereceğini tahmin etmelerine yardımcı olur.
Sentetik verinin de bu ölçekleme yasalarına uyup uymadığını belirlemek için Microsoft Research Asia, ön eğitim verilerinden ölçeklenebilir sentetik veri üretebilen SynthLLM sistemini geliştirdi. Yoğun testlerin ardından, araştırma ekibi bu yasaların sentetik veriler için de geçerli olduğunu doğruladı. Bu bulgu, sentetik verilerin büyük dil modellerinin eğitimi ve optimizasyonunda çok daha önemli bir rol oynamasının önünü açıyor.
Sentetik veriler yeni bir ölçekleme deseni izliyor
Araştırmacılar, SynthLLM çerçevesini kullanarak sentetik verilerle ince ayar yapılan büyük dil modellerinin (LLM), düzeltilmiş bir versiyon olan düzeltilmiş ölçekleme yasasına uyduğunu gösterdi. Temel bulgular şunlardır:
-
Öngörülebilir performans ölçeklemesi: SynthLLM tarafından üretilen sentetik veriler, farklı model boyutları arasında tutarlı performans artışları sağlıyor. Bu öngörülebilirlik, araştırmacıların eğitim veri hacmini model boyutuna daha etkili şekilde uyarlamalarına yardımcı oluyor.
-
Performans 300 milyar token’da dengeleniyor: Bu noktadan sonra daha fazla sentetik veri eklemek yalnızca küçük iyileştirmeler sağlıyor. Bu doyma noktasının belirlenmesi, eğitim stratejilerinin optimize edilmesini kolaylaştırıyor.
-
Daha büyük modeller daha az veriye ihtiyaç duyuyor: Sekiz milyar parametreli bir model yaklaşık bir trilyon token ile neredeyse en iyi performansına ulaşırken, üç milyar parametreli daha küçük bir modelin aynı seviyeye ulaşması için dört trilyon token gerekiyor. Bu ters yönlü eğilim, modellerin verimli şekilde inşa edilmesi ve ölçeklendirilmesi konusunda önemli bir yol gösterici sunuyor.
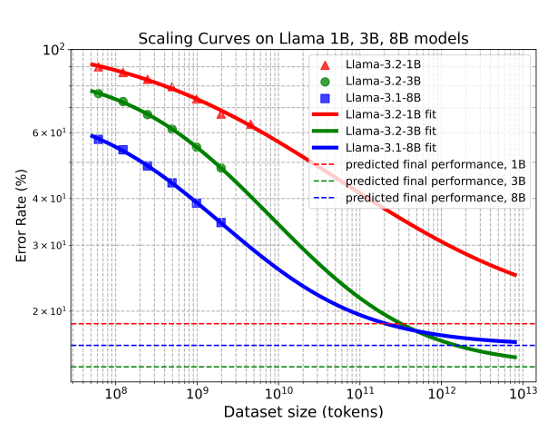
Şekil 1. SynthLLM tarafından üretilen sentetik veriler, model boyutları fark etmeksizin düzeltilmiş ölçekleme yasasına tutarlı bir şekilde uymaktadır. Eğriler doğruluk oranlarını değil, hata oranlarını temsil etmektedir.
SynthLLM: Çeşitli Sentetik Veri Setleri İçin Ölçeklenebilir Bir Yaklaşım
Dil modellerini eğitmenin yaygın yöntemlerinden biri, özellikle akıl yürütme, problem çözme ya da bilgi geri çağırma gibi görevlerde, soru-cevap çiftlerini veri olarak kullanmaktır. Geleneksel olarak bu tür sentetik veri kümeleri, az sayıda elle etiketlenmiş örnek üzerine kuruludur; bu da hem ölçeklemeyi hem de çeşitliliği sınırlar. Buna karşılık, ön eğitimde kullanılan geniş ve çeşitli web belge koleksiyonları, daha ölçeklenebilir sentetik veriler oluşturmak için yeterince değerlendirilmemiş bir kaynak sunar.
SynthLLM, bu potansiyeli üç aşamalı bir süreçle değerlendirir:
-
Alanla ilgili yüksek kaliteli web içeriğinin seçilmesi,
-
Açık kaynak LLM’lerle üç tamamlayıcı yöntem kullanarak çeşitliliği giderek artıran istemler (prompts) oluşturulması,
-
Her istem için yanıtlar üretilerek eksiksiz veri örneklerinin oluşturulması.
Önceki yöntemler çoğunlukla geri çeviri (back-translation) ya da basit soru çıkarımı gibi tekniklere dayanırken, SynthLLM, çoklu belgelerden üst düzey kavramları tanımlayıp yeniden birleştirmek için graf algoritmaları kullanır. Bu sayede daha derin kavramsal bağlantılar kurulabilir ve sınırlı sayıdaki referans belgeden daha verimli bir şekilde çeşitli sorular üretilerek ölçekleme yapılabilir.
Sonuç mu?
Daha geniş yelpazede, daha çeşitli sentetik sorular.
Şekil 2, SynthLLM’in çok adımlı sürecinin nasıl daha fazla çeşitlilik sağladığını göstermektedir.
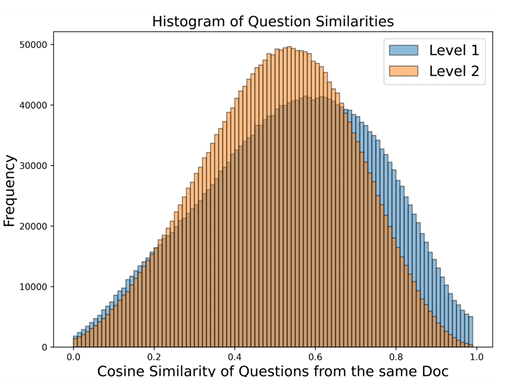
Şekil 2. Aynı belge içerisindeki sorular arasındaki benzerliği gösteren çubuk grafik.
Mevcut eğitim verilerini genişletme yöntemleriyle doğrudan karşılaştırıldığında, SynthLLM’in bilgi odaklı yaklaşımı, sınırlı kaynak materyali çok daha verimli kullanarak yüksek kaliteli sorular üretmektedir.
Bu sayede modeller, kıyaslama testlerinde (benchmark’larda) daha güçlü performans sergilemektedir.
Şekil 3, bu gelişmiş performansı görsel olarak ortaya koymaktadır.
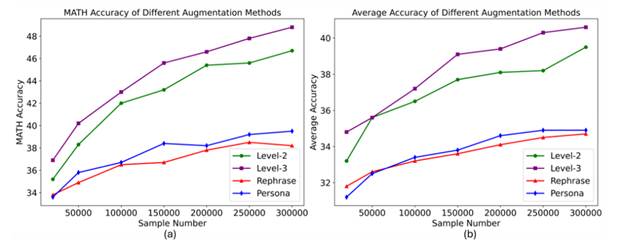
Şekil 3.
(a) Diğer veri genişletme yöntemlerinin MATH benchmark testindeki performansı.
(b) Birden fazla benchmark testi üzerinden ölçülen ortalama model performansı
(x ekseni: örnek kimliği (sample ID); y ekseni: doğruluk oranı (accuracy))
Eğitim Verisi İçin Yenilenebilir Bir Kaynak
Veri duvarı giderek yükselirken, sentetik veri, yapay zeka geliştirme için vazgeçilmez bir kaynak haline geliyor. Bu veriler ölçeklenebilir, hızlı üretilebilir, maliyet açısından verimlidir ve elle etiketlemeye gerek duymaz bu da onu artan veri kıtlığına karşı pratik bir çözüm haline getiriyor.
Sentetik verinin değeri pek çok alana yayılıyor:
-
Sağlık alanında, hasta mahremiyetini korur.
-
Otonom sürüşte, sanal simülasyonlara güç sağlar.
-
Eğitimde, talebe bağlı olarak milyonlarca matematik problemi oluşturulmasına olanak tanır.
SynthLLM, sentetik veri üretimini sadeleştirerek araştırmacıların bu verileri LLM eğitiminde daha etkin kullanmalarına yardımcı olur. Bu framework, kod üretimi, fizik, kimya ve sağlık gibi alanlara kolayca uyarlanabilir, bu da onu disiplinler arası araştırmalarda kullanılabilecek güçlü bir araç haline getirir.
Araştırmacılar şu anda SynthLLM’in verimliliğini artırmak ve devam eden ön eğitim (continued pretraining) süreçlerinde nasıl kullanılabileceğini keşfetmek için çalışmalarını sürdürüyor. Bu çabalar, sentetik verinin kalitesini yükseltmeyi ve etkisini genişletmeyi hedefliyor. Böylece yapay zekanın bir sonraki büyük gelişim dalgasına katkı sağlıyor.


